← Volver a casosMachine Learning / Inventory Intelligence
DemandOS
Sistema de machine learning para previsión de demanda, riesgo de stockout y recomendaciones internas de reposición.
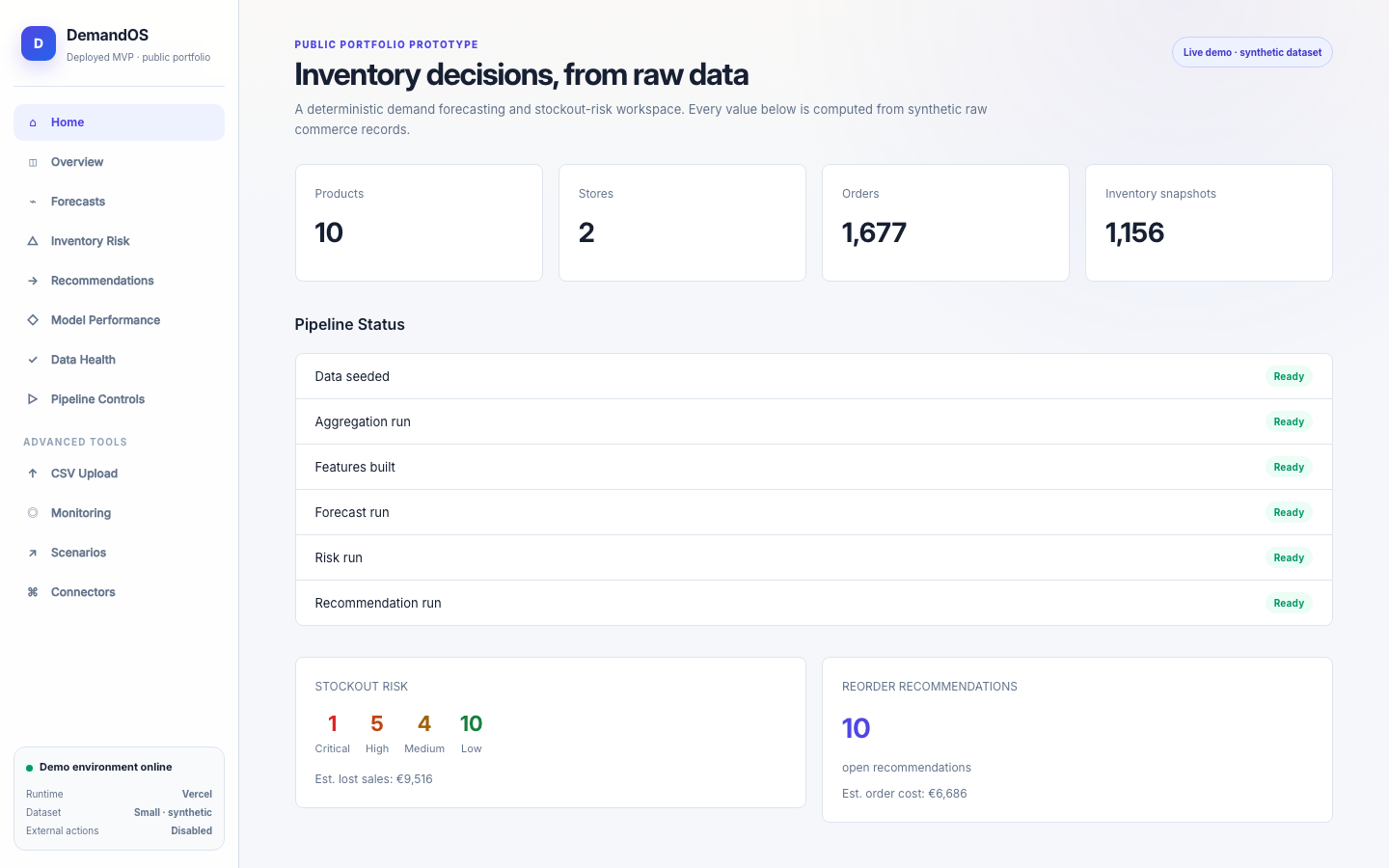
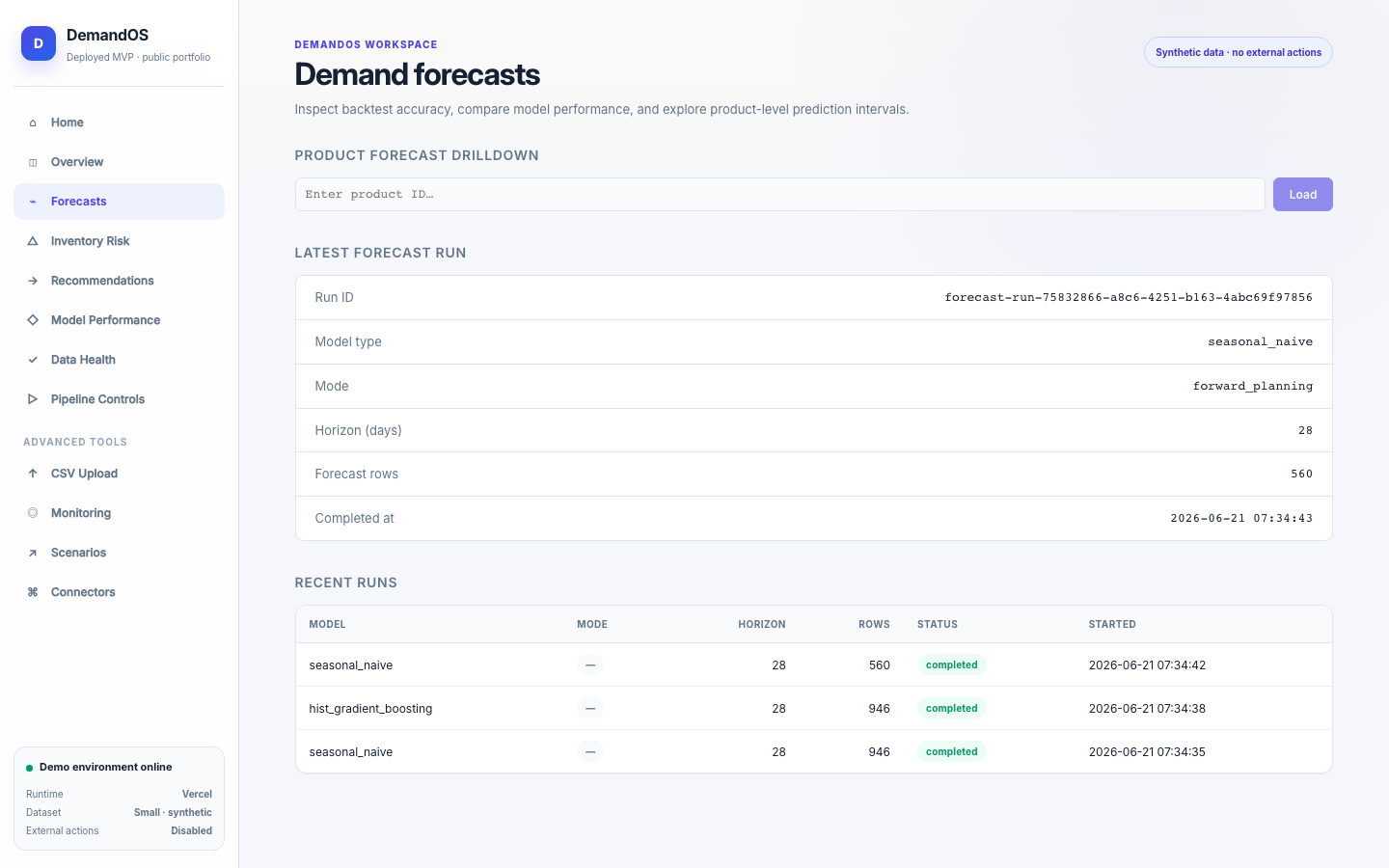
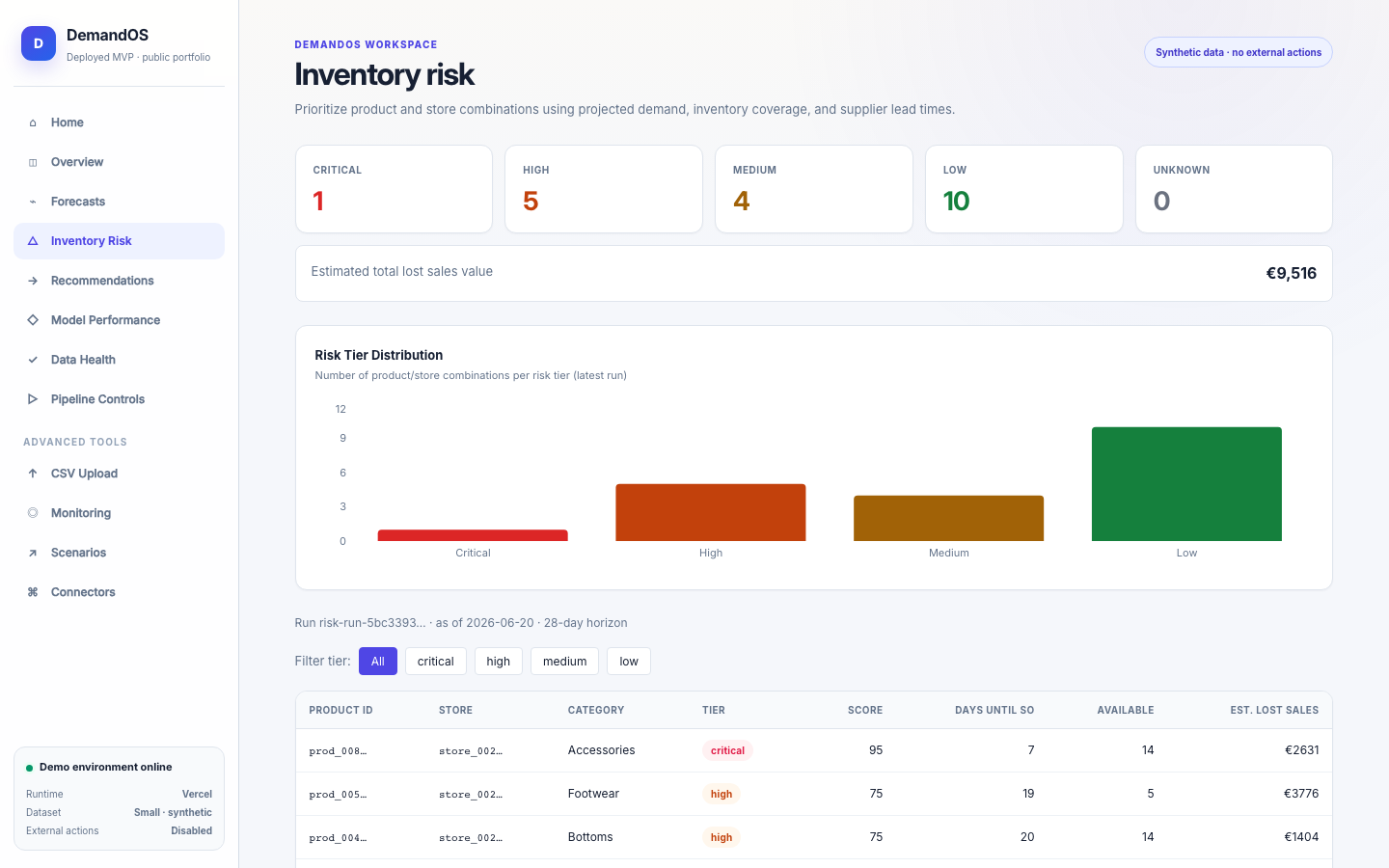
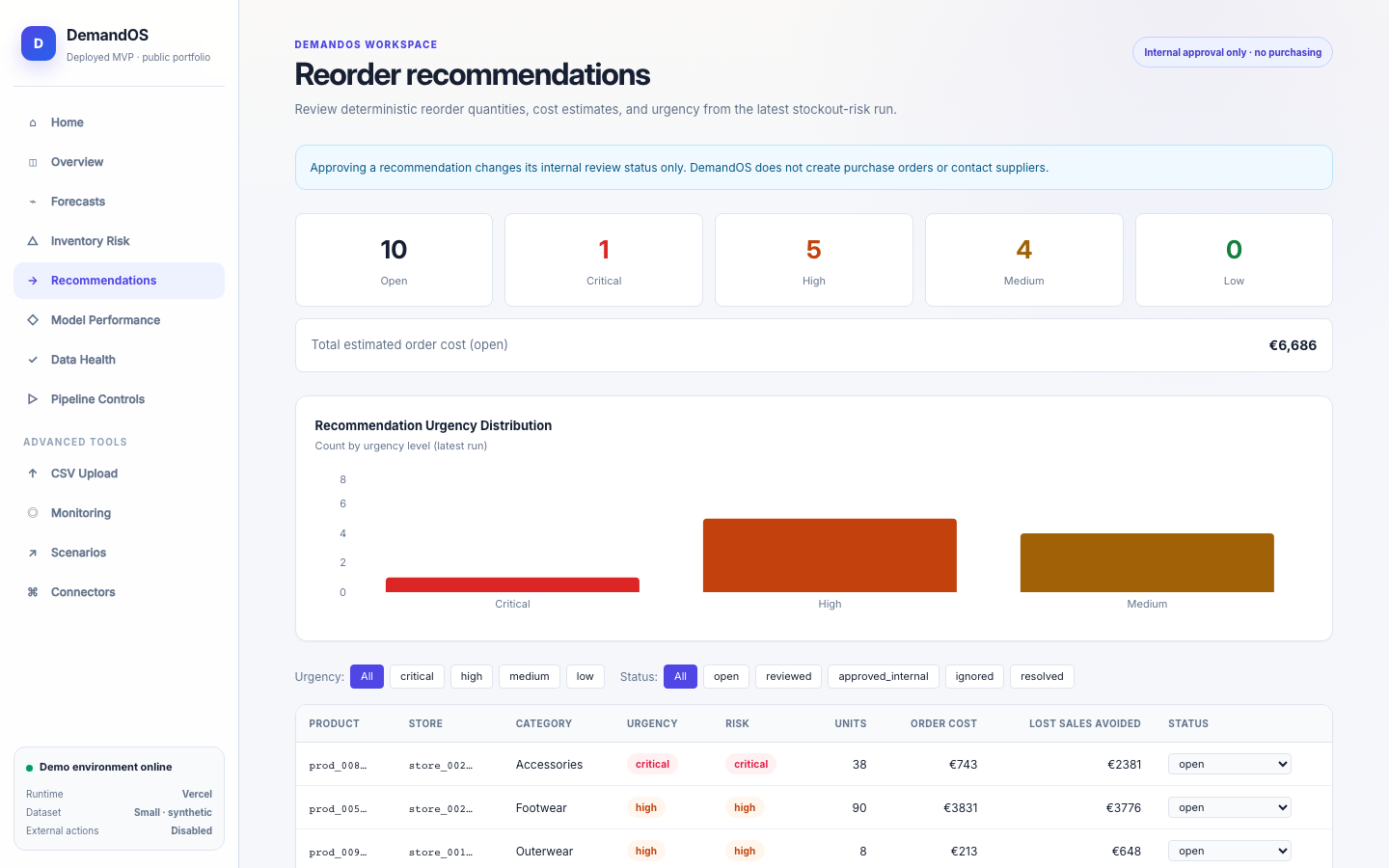
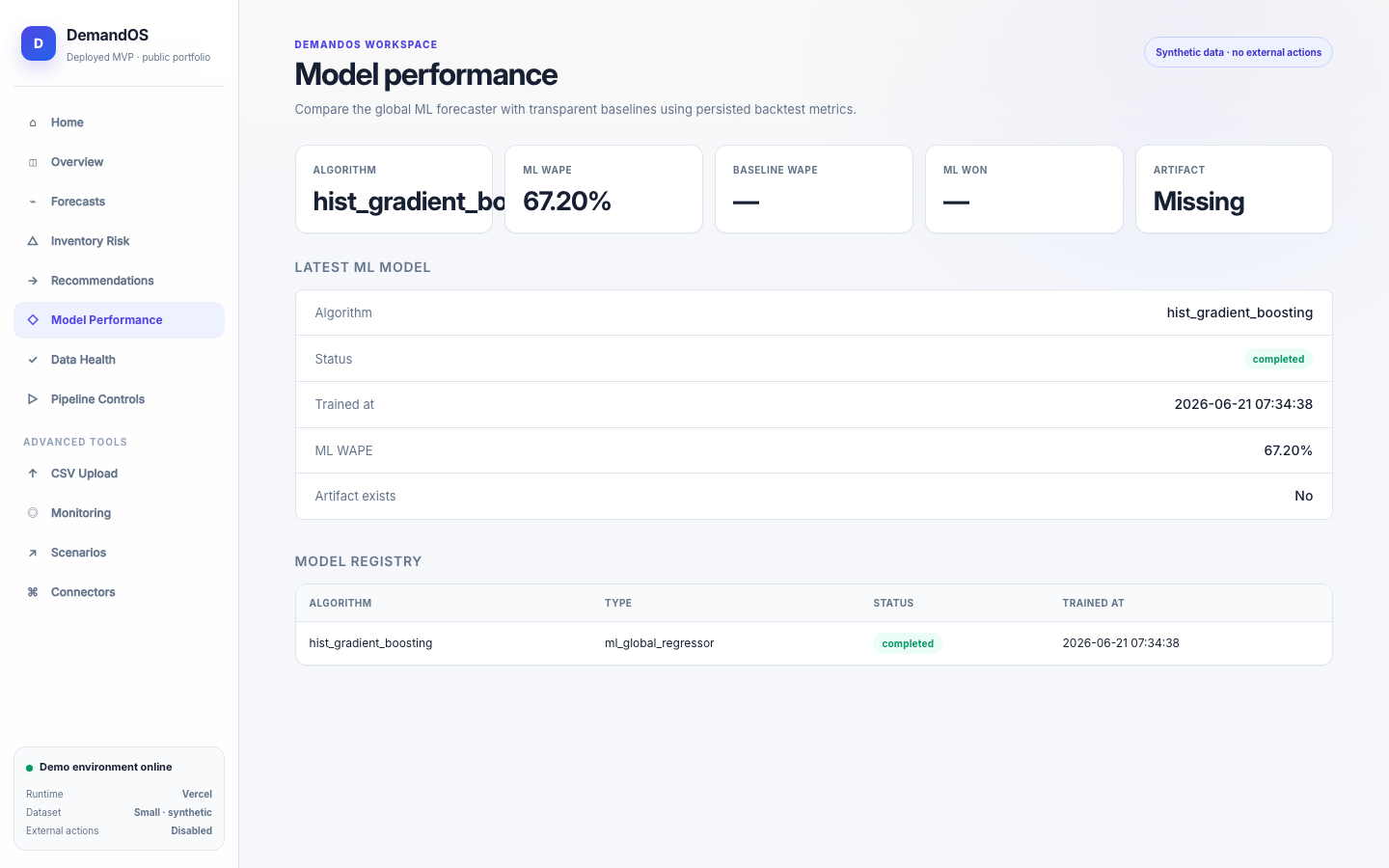
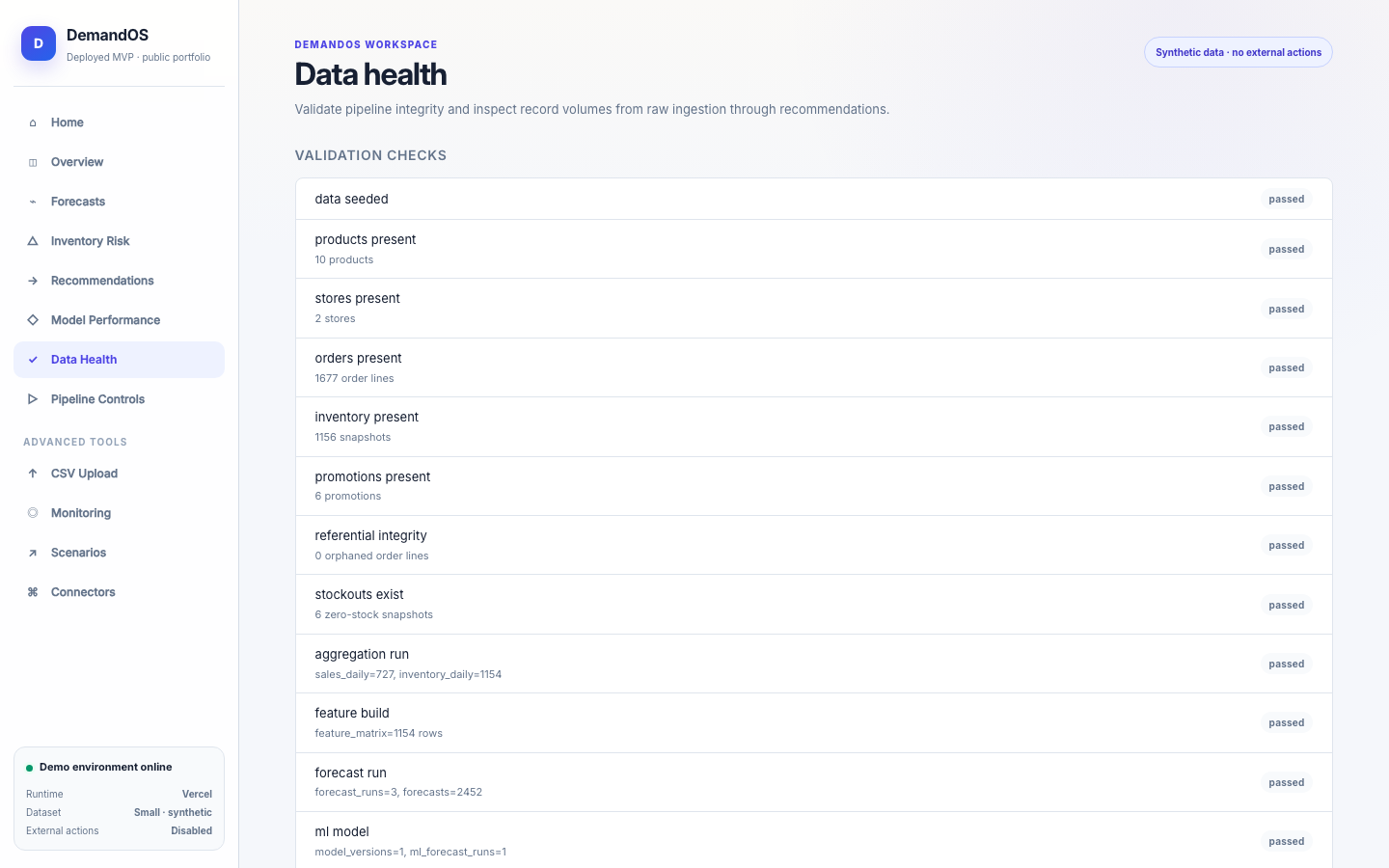
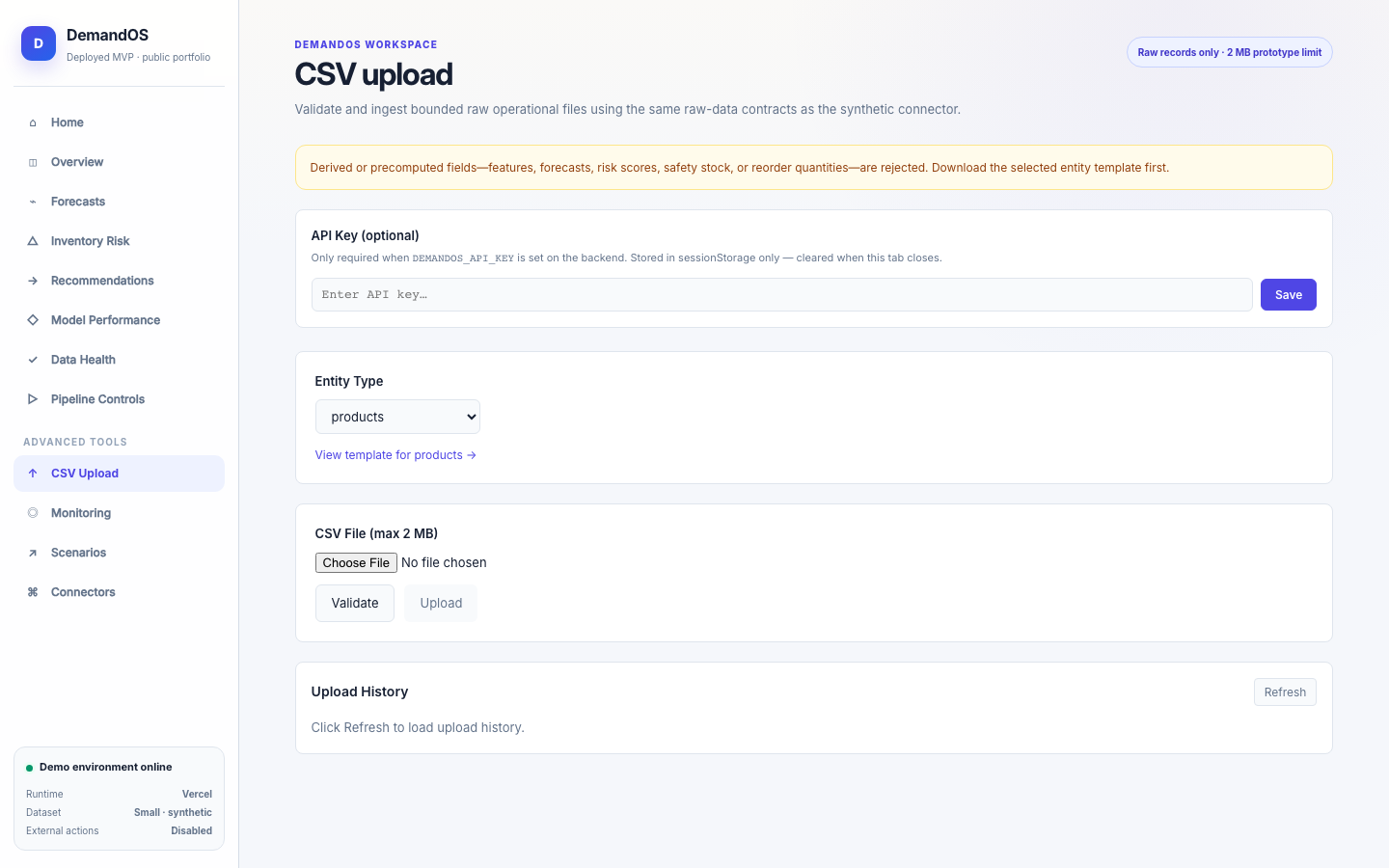
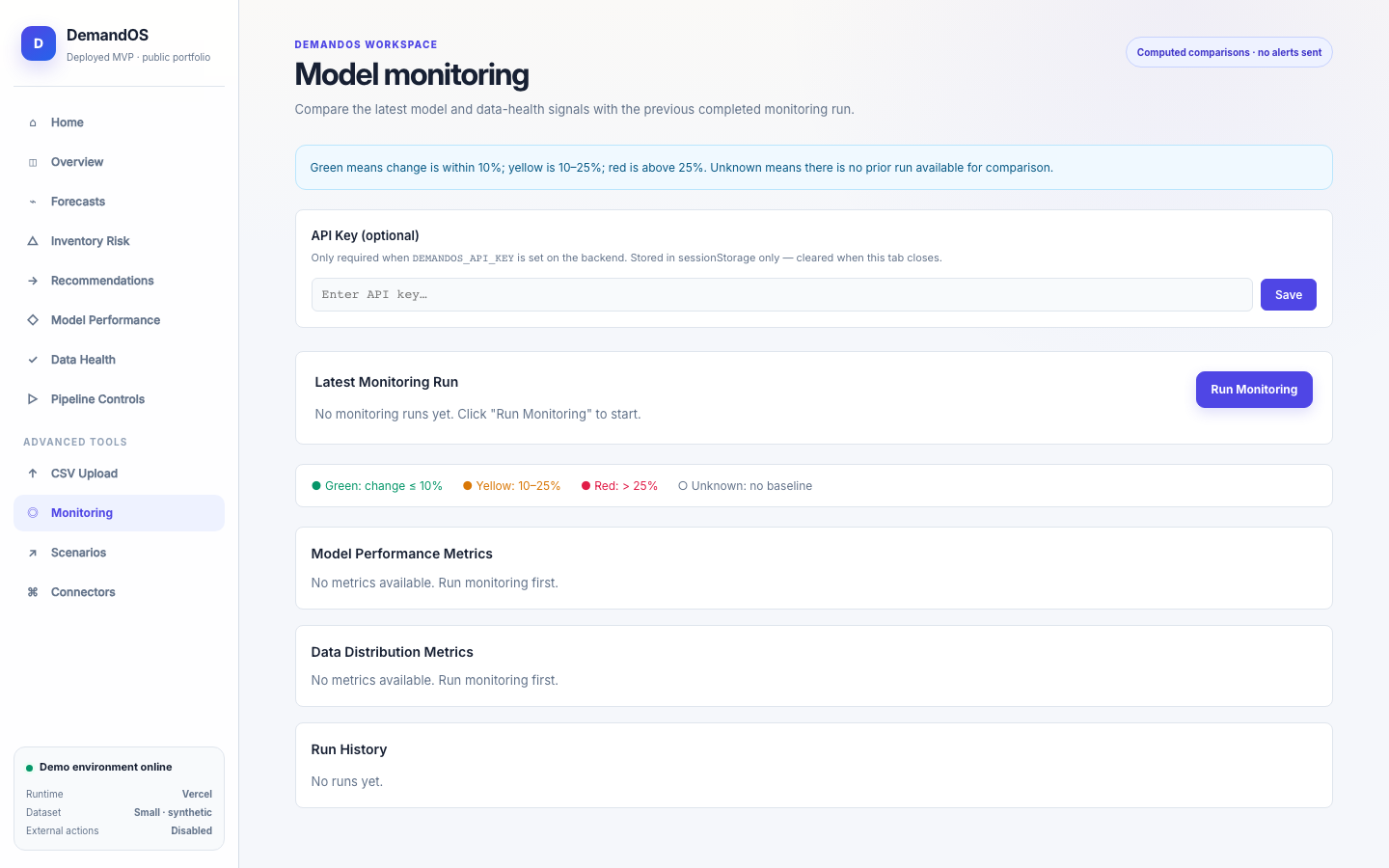
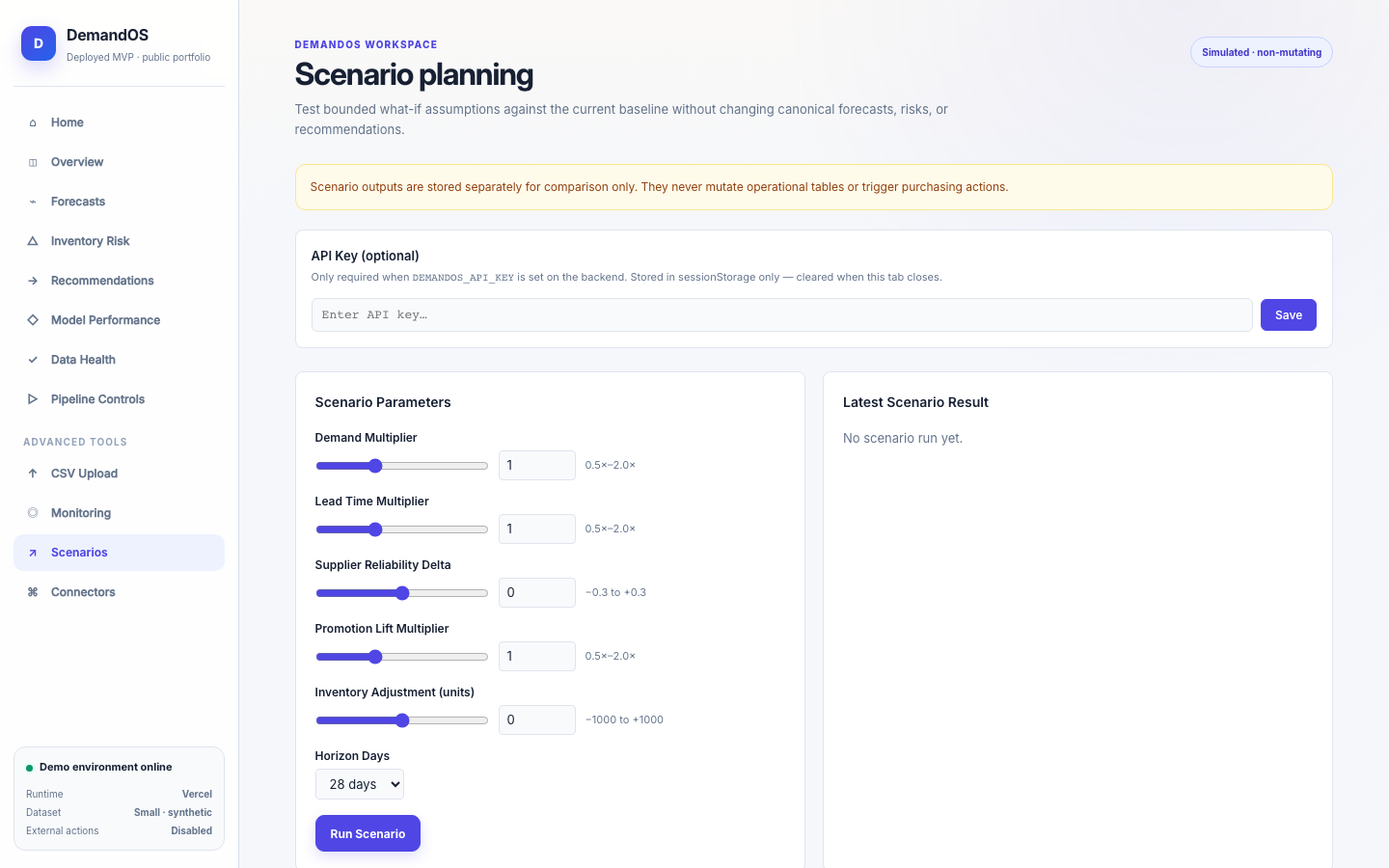
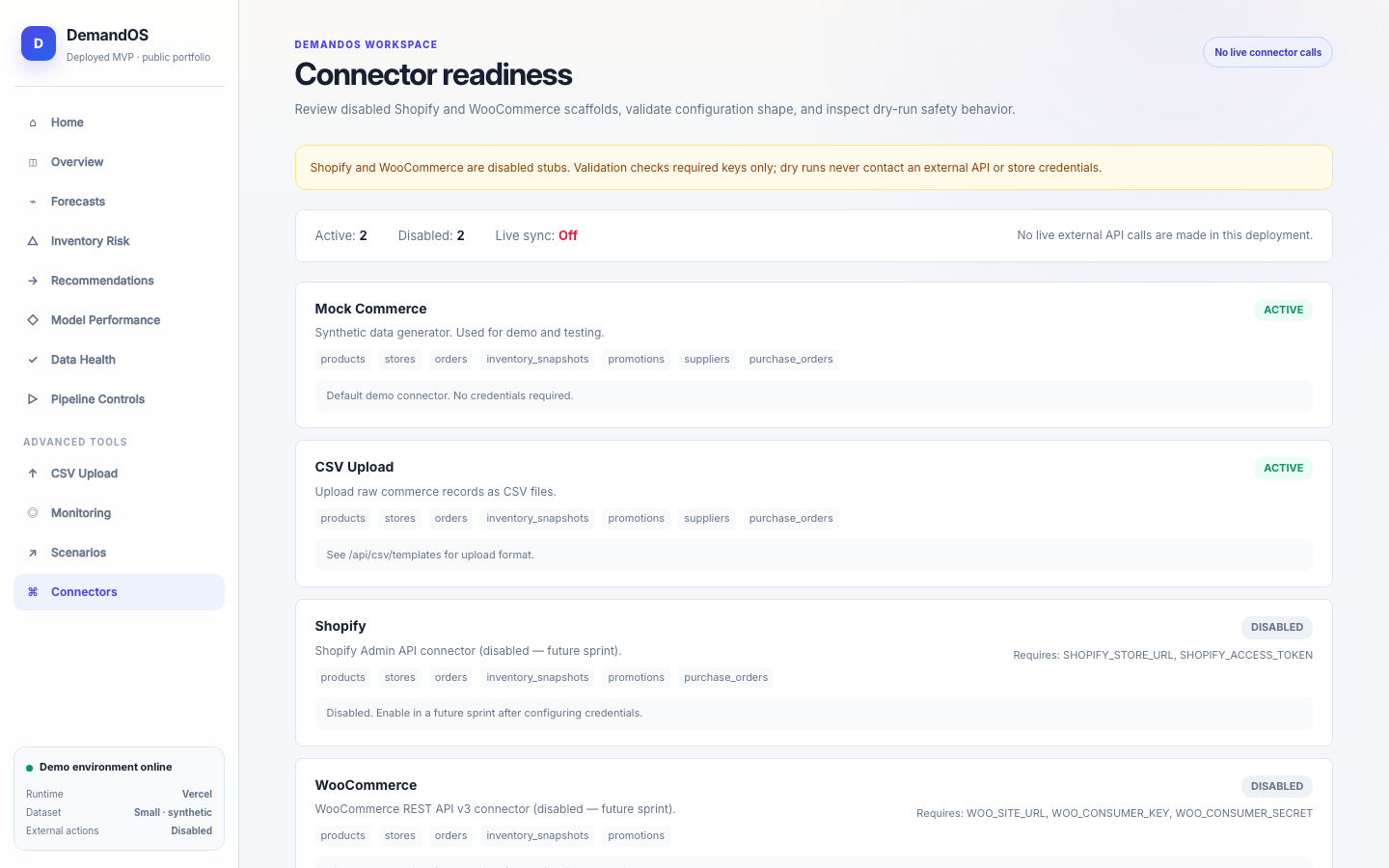
DemandOS convierte datos operativos sintéticos —productos, tiendas, pedidos, inventario, promociones y proveedores— en features leakage-safe, forecasts, métricas de modelo, riesgos de stockout y recomendaciones de reposición. Está desplegado como prototipo público en Vercel con Neon Postgres y no ejecuta compras reales ni acciones externas.
Datos sintéticos operativosForecasting MLNeon + VercelSin acciones externas
Machine LearningForecastingInventory IntelligenceData ProductFastAPINext.jsscikit-learnNeon PostgresVercelSynthetic DataMonitoringScenario Planning